
Over the past four weeks I've worked with half a dozen companies and all of them are facing the same issue.
How do we ingest data and refine it for AI agent workloads?
AI agents are phenomenal. Their capabilities are endless it seems, and it's no longer a question of whether an agent can do the work. We've already proven that part.
The next hurdle is the data. This isn't just what I'm seeing in my own work. Dun & Bradstreet ran an AI Momentum Survey earlier this year.
97% of organizations have active AI initiatives.
Only 5% feel their data is ready to actually support them [1].
Wing Venture Capital surveyed enterprise leaders and found data was the #1 or #2 challenge depending on company size [2].
Model selection didn't make either list. Jensen Huang put it most directly at CES this year: "The bottleneck is shifting from compute to context management" [3].
Why agents are different
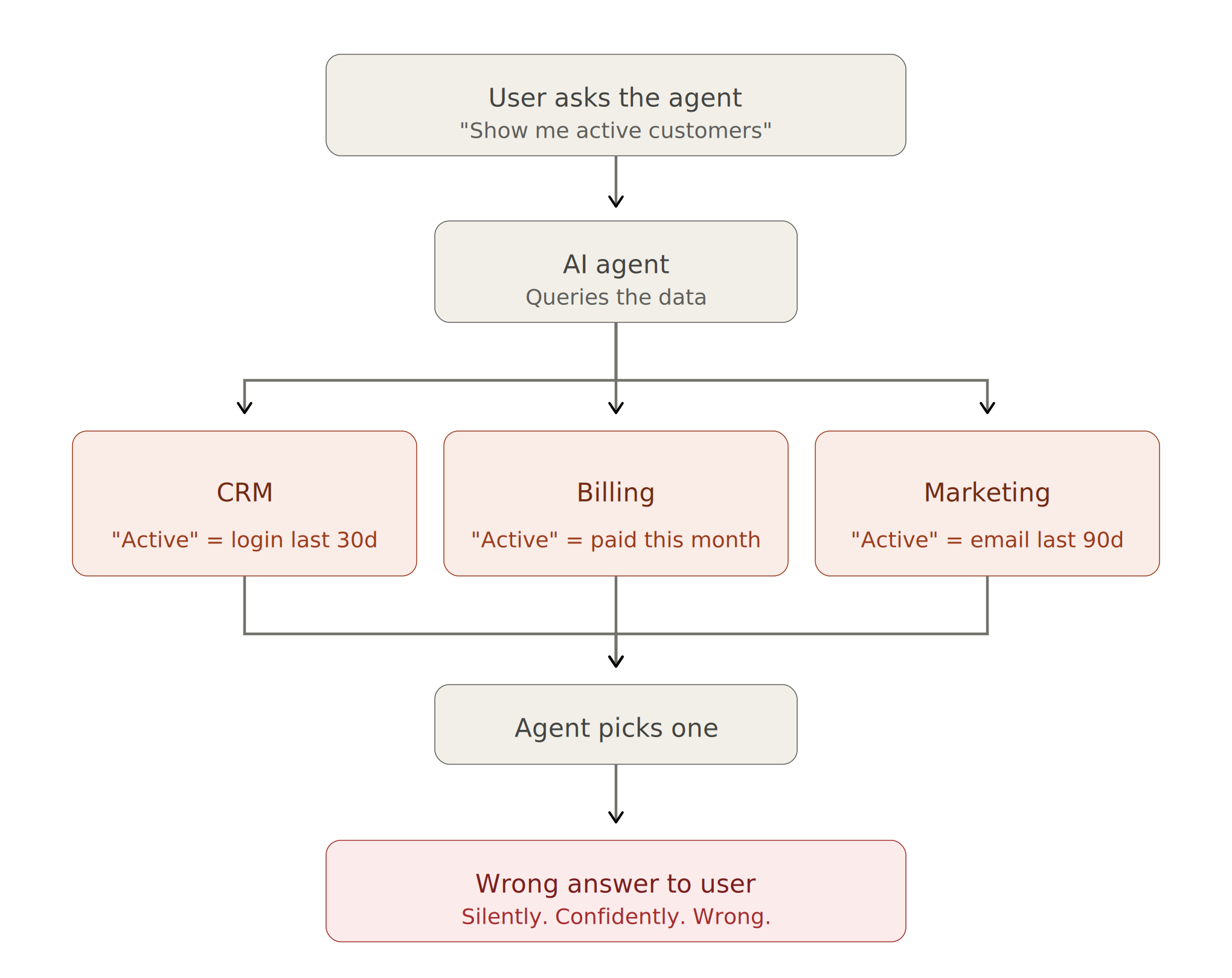
If you've ever built a BI dashboard, you already know the data engineering pain. Joins. Schemas. Stale snapshots. Definitions that drift across teams. None of this is new.
What's new is the consumer.
A human analyst can reason around the rough edges. They see that "customer" means three different things in three different tables and they mentally adjust. An agent can't do that. It treats your schema as ground truth. If you have three definitions of "customer" floating around, the agent picks one and acts on it. Silently. Confidently. Wrong.
That's the entire reason data engineering is about to matter more, not less. As the Datumo team puts it, for AI agents ambiguity becomes silent failure [4].
What "data ready" actually means now
For agentic workloads, "data ready" has a much sharper definition than it used to. From what I'm seeing across these projects:
→ Semantic clarity. One canonical definition per entity, machine-readable, not living in tribal knowledge.
→ Freshness. Agents make decisions in real time, so yesterday's snapshot is often a liability.
→ Lineage. So you can trace bad agent behavior back to the data that caused it.
→ Schema stability. Fivetran's 2026 benchmark put the average large enterprise at roughly 4.7 pipeline failures per month, with each one taking close to 13 hours to resolve [5].
→ Retrieval-shaped storage. Most analytical warehouses aren't built for the kind of millisecond lookups an agent needs every few hundred requests.
You can demo an agent without any of these. You can't ship one reliably without all of them.
The shift
The role used to be about moving data correctly and on time. Reliable pipelines. Scalable warehouses. Clean ETL. Necessary work, but not where the value sat.
The new version is about defining meaning. The Datumo team frames it well: the modern data engineer's focus is shifting "from writing queries to designing meaning." The bottleneck is no longer coding speed. It's conceptual clarity [4].
And the people who can do that well are going to be more valuable than the people writing agent orchestration logic. Because the orchestration is increasingly being written by other agents. The semantic layer underneath can't be.
The prediction
My prediction is that data engineering is about to be the most valuable skill in AI over the next six months. Not the version from 2018. The new one.
AI is only as good as the data we give it. That sentence used to be a cliché. It's about to become an org chart.
What I'm working on right now
One challenge I'm working through with portfolio companies is determining the most optimal data structure for gold data marts. The ones the downstream AI agent pulls from directly.
It's a different shape than what feeds BI dashboards or traditional APIs. Agents have different access patterns, different tolerance for ambiguity, different needs around freshness and lineage. The same gold mart that worked beautifully for an analyst can fall apart the moment an agent is the consumer.
Have you solved this one?
References
[1] CIO Magazine, citing the Dun & Bradstreet AI Momentum Survey. "Nearly every enterprise is investing in AI, but only 5% say their data is ready." May 2026. https://www.cio.com/article/4170978/nearly-every-enterprise-is-investing-in-ai-but-only-5-say-their-data-is-ready.html
[2] Wing Venture Capital. "The State of AI in the Enterprise." https://www.wing.vc/content/the-state-of-ai-in-the-enterprise
[3] Jensen Huang, NVIDIA, keynote remarks at CES 2026. Quote reported across multiple industry outlets, including Alibaba Cloud Community: "AI Trends Reshaping Data Engineering in 2026." https://www.alibabacloud.com/blog/ai-trends-reshaping-data-engineering-in-2026_602816
[4] Datumo. "Data Engineer 2026: AI Agents, context-aware Data Systems & the future of data engineering." February 2026. https://www.datumo.io/blog/essential-skills-for-data-engineers-2026
[5] Fivetran 2026 Enterprise Data Infrastructure Benchmark, cited in Atlan: "AI Agents for Data Engineering: 2026 Reliability Guide." https://atlan.com/know/ai-agents-for-data-engineering/
Further reading
Salesforce. "2026 State of Data and Analytics Report." Notes that 84% of data leaders agree AI is only as good as its inputs, while estimating roughly a quarter of organizational data is untrustworthy. https://www.salesforce.com/news/stories/data-analytics-trends-2026/
PwC. "2026 Digital Trends in Operations Survey." 87% of surveyed leaders say poor data quality has hampered their digital initiatives. https://www.pwc.com/us/en/services/consulting/supply-chain-operations/library/digital-trends-operations-survey.html
Atlan. "AI Agents for Data Engineering: 2026 Reliability Guide." Practical guide to context layers, semantic models, and agent reliability infrastructure. https://atlan.com/know/ai-agents-for-data-engineering/
Comments
No comments yet. Be the first.